想知道我們Training出來的模型好壞,
就要選用適當指標來評估,
通常分成「迴歸」、「分類」兩大類問題。
觀察預測值 (Prediction) 和實際值 (Ground Truth) 的差距
MAE, Mean Absolute Error, 範圍:[0, ∞]

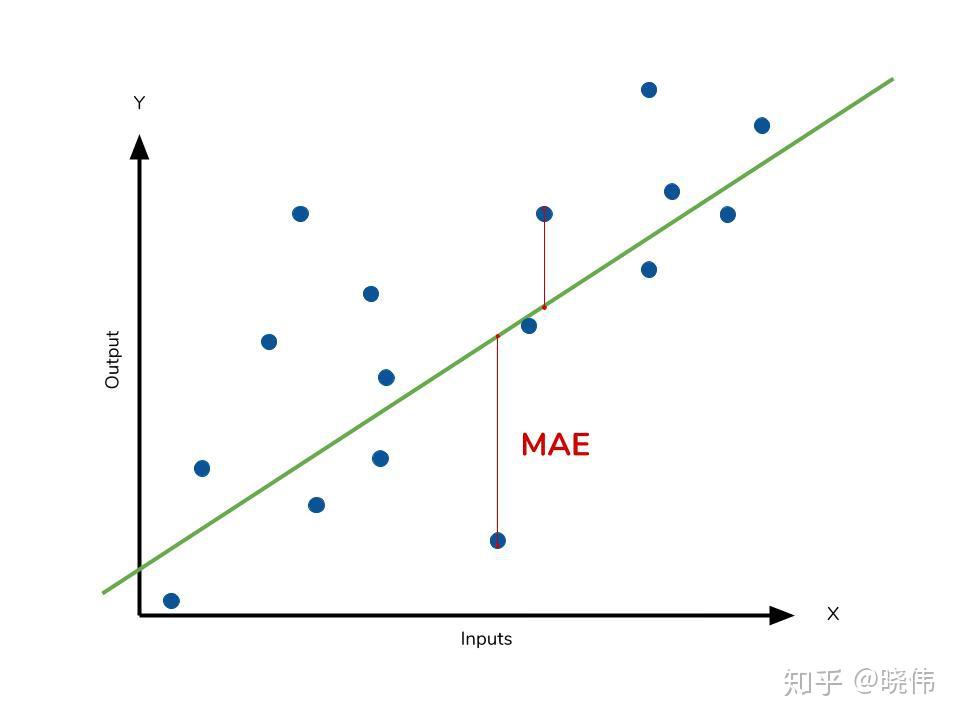
MSE, Mean Square Error, 範圍:[0, ∞]
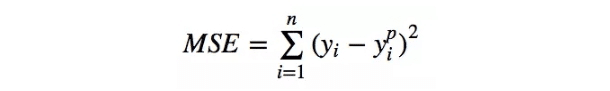
參考:如何選擇回歸損失函數?
評估實際值和預測值的距離,例如「問我們預測出來的排名,距離實際的排名差了多少」
| MAE | MSE | |
|---|---|---|
| 特性 | 較同原資料 | 容易被放大 |
| 離群值 | 不適 | 適合 |
| 用途 | 適合商業模型 | |
| 準確 | 數字越小 | 數字越小 |
| 迴歸 | 收斂慢,次數多 | 收斂快,次數少 |
| 梯形 | 較平 | 較陡 |
R-square, 範圍:[0, 1]
參考決定係數(R平方)解釋,
R平方由下式給出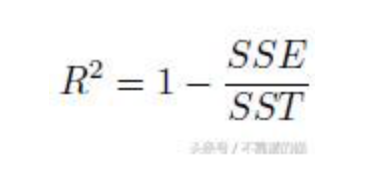
其中SSE是我們的回歸模型的誤差平方的總和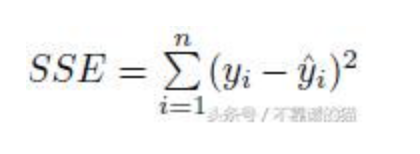
而SST是我們的基礎模型的誤差平方的總和。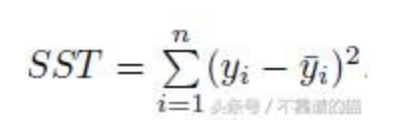
R平方= 1-1 = 0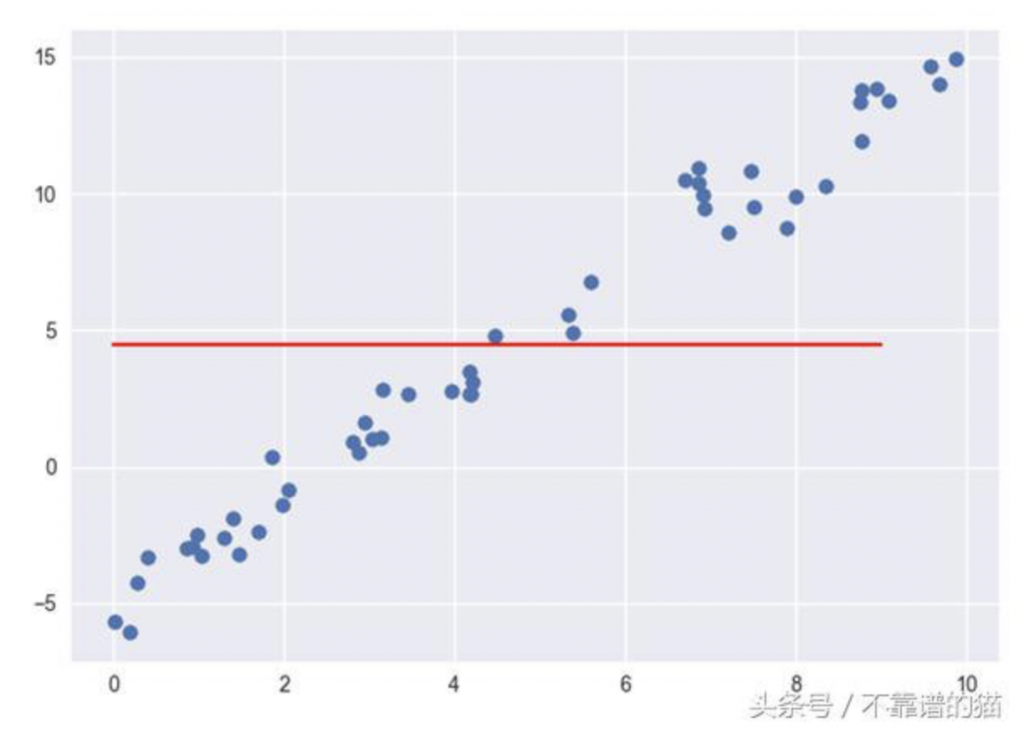
R平方= 1-0 = 1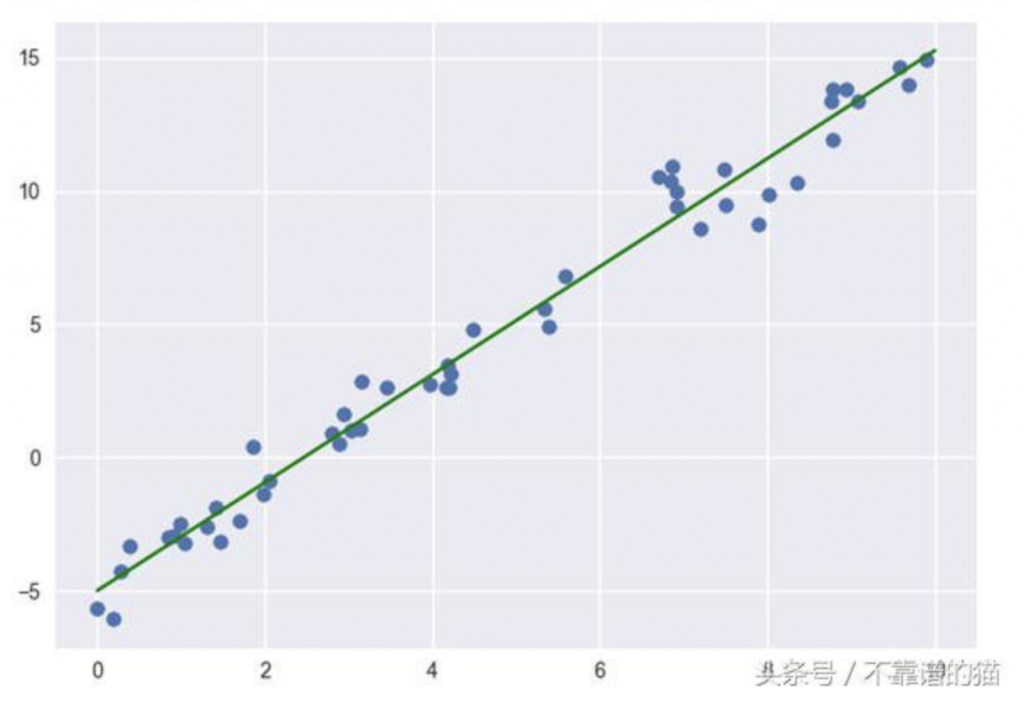
如果R平方= 0.93,則意味著因變量Y的93%變化由我們模型中存在的自變量解釋。
觀察預測值 (Prediction) 和實際值 (Ground Truth) 的正確程度
AUC, Area Under Curve, 範圍:[0, 1]
让我们来看在實際有100个阳性和100个阴性的案例時,四種預測方法(可能是四種分類器,或是同一分類器的四種閾值設定)的結果差異: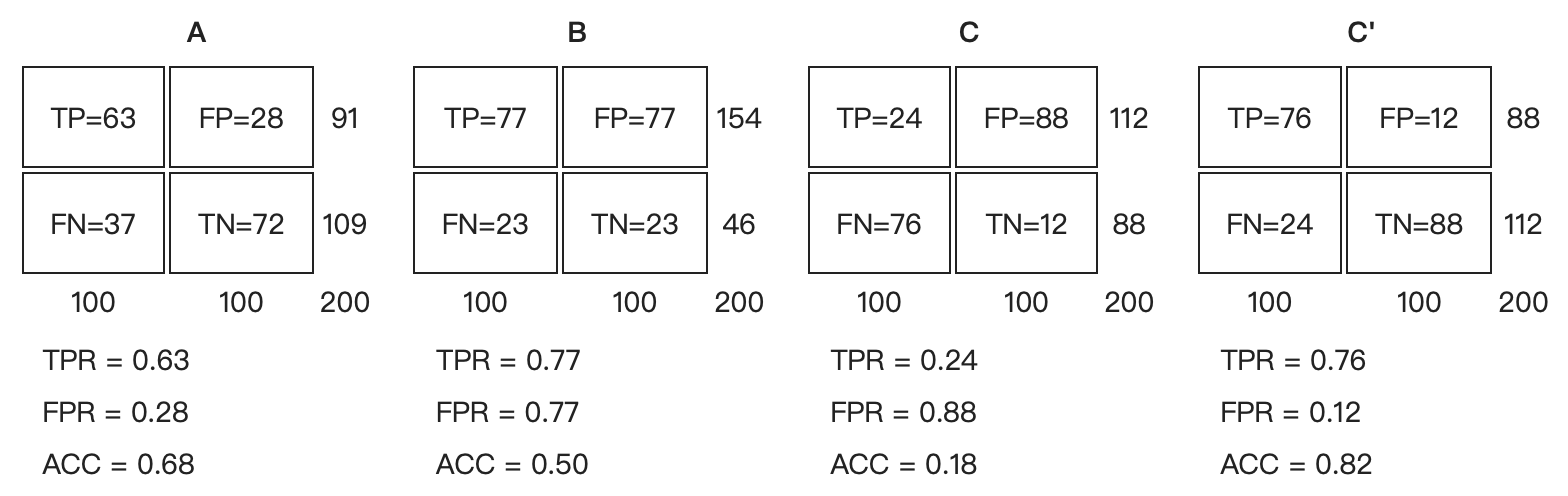
將這4種结果畫在ROC空间裡:
點與随机猜测线的距離,是預測力的指標:离左上角越近的點預測(診斷)準確率越高。離右下角越近的點,预测越不準。
A方法。B方法的结果位於随机猜测线(對角線)上,在例子中我们可以看到B的準確度(ACC,定義見前面表格)是50%。C方法雖然預測準確度最差,甚至劣於隨機分類,也就是低於0.5(低於對角線)。然而,当将C以 (0.5, 0.5) 為中點作一个镜像后,C'的结果甚至要比A还要好。这个作镜像的方法,简单說,不管C(或任何ROC點低於對角線的情況)预测了什么,就做相反的結論。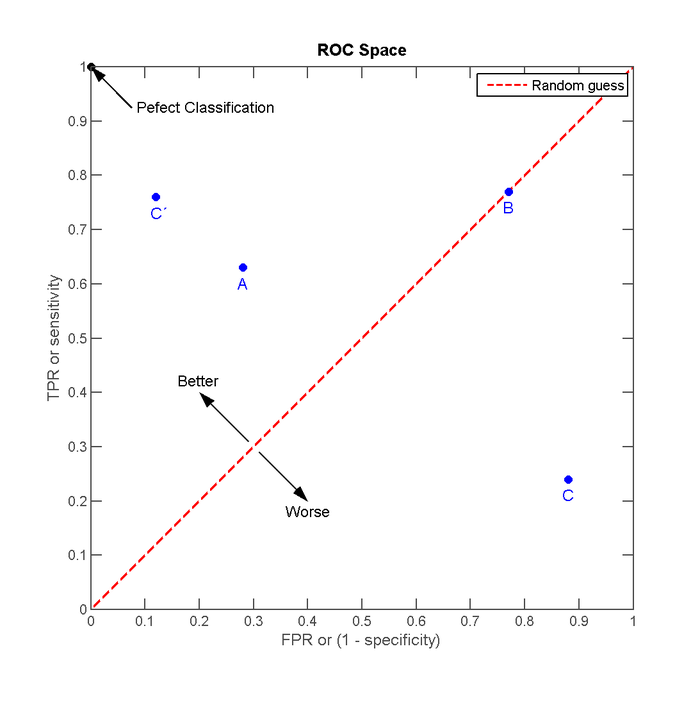
同一個二元分類模型的閾值可能設定為高或低,每種閾值的設定會得出不同的FPR和TPR

ROC曲線下方的面積 Area under the Curve of ROC (AUC ROC)
模型優劣的指標0~1之間。
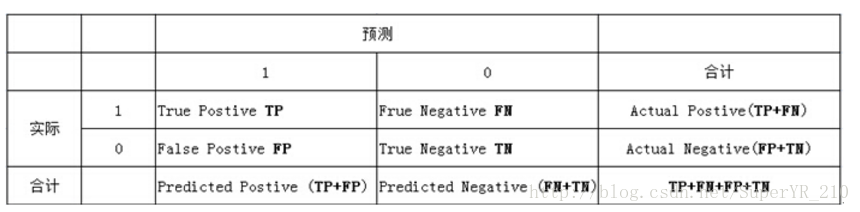
F1-Score (Precision, Recall), 範圍:[0, 1] ,混淆矩陣 (Confusion Matrix) 相關
參考:深度學習中、TP FP FN TN precision Recall Accuracy
True Positive(TP):預測爲正例,實際爲正例
False Positive(FP):預測爲正例,實際爲負例
True Negative(TN):預測爲負例,實際爲負例
False Negative(FN):預測爲負例,實際爲正例

accuracy
>正確預測的樣本數佔總預測樣本數的比值,它不考慮預測的樣本是正例還是負例。考慮全部樣本。
precision
>正確預測的正樣本數佔所有預測爲正樣本的數量的比值,也就是說所有預測爲正樣本的樣本中有多少是真正的正樣本。只關注預測爲正樣本的部份。
Recall
> 正確預測的正樣本數佔真實正樣本總數的比值,也就是從這些樣本中能夠正確找出多少個正樣本。
F-score
>相當於precision和recall的調和平均,recall和precision任何一個數值減小,F-score都會減小,反之,亦然。
specificity
>相對於sensitivity(recall)而言的,指的是正確預測的負樣本數佔真實負樣本總數的比值,也就是我能從這些樣本中能夠正確找出多少個負樣本。
模型指標評估,
就是在衡量預測值和實際值的差異,
基本上誤差越小越好喔!
以上,打完收工。